.svg)
Back
November 13, 2025
Mapping the Safety Gradient: Cross-Model Analysis of Adversarial Vulnerabilities in Large Language Models

Ava Fitoussy
UC Berkeley

Liu Zhang
Harvard University
Abstract
Despite extensive investment in alignment training, large language models can still be manipulated into generating unsafe, biased, or misleading content when exposed to adversarial prompts. This study applies structured red teaming across five leading systems, GPT-5 Auto,Claude Opus 4.1, Gemini 2.5 Flash, Llama 4 (Scout), and Grok 4, to systematically evaluate their safety resilience under human-crafted adversarial scenarios. By diversifying attack types, we identify failure modes that conventional automated benchmarks overlook. In addition to quantifying risk, we construct an expert-annotated dataset spanning multiple safety domains to support reproducible analysis. Our cross-model comparisons reveal a clear safety gradient, with proprietary models generally outperforming open-weight systems, and complex or context-manipulated prompts posing the greatest risks. These findings provide actionable insights for improving alignment strategies, refining refusal calibration, and guiding future safety evaluations.
1. Introduction
Recent advances in large language models (LLMs) have driven widespread adoption across scientific, industrial, and consumer domains, but they also present persistent safety and security concerns. Despite extensive investment in alignment training, models can still be manipulated into generating unsafe, biased, or misleading content when exposed to adversarial prompts. Red teaming has emerged as a critical methodology for evaluating these vulnerabilities. Borrowing its name from cybersecurity and military practice, red teaming in the context of AI involves systematically probing models in order to identify weaknesses in their protective mechanisms. This study applies structured red teaming across five leading LLMs: GPT-5 Auto, Claude Opus 4.1, Gemini 2.5 Flash, Llama 4 (Scout), and Grok 4. The objectives of this work are threefold. First, we aim to systematically evaluate the safety resilience of the leading models when exposed to adversarial human-crafted prompts. By diversifying attach types, our objective was to identify failure modes that conventional automated benchmarks overlook. Second, in addition to qualify risk, we also seek to build a high-quality, expert-annotated dataset spanning multiple risk domains. Finally, we aim to map the emerging safety gradient among models and generate actionable insights to inform future alignment, training, and evaluation strategies through cross-model comparisons. By approaching models as black-box systems and testing them with creativity drawn from diverse areas of expertise, this project highlights not only points of failure but also the ways in which adversarial strategies exploit gaps in alignment.
2. Taxonomy and Evaluation Framework
2.1 Taxonomy of Adversarial Attacks
To evaluate model performance consistently, adversarial attempts were categorized using a taxonomy that captures the nature of the attack, the domain of risk, and the cultural or linguistic factors present in the prompt. This taxonomy builds on prior alignment research but was adapted to reflect the techniques most relevant for human red teamers.Attack intent is the first dimension of the taxonomy. Direct harmful requests refer to overtly dangerous instructions that models are expected to reject. Obfuscated or indirect attacks disguise malicious intent in fictional, hypothetical,or role-played scenarios. Jailbreak attempts seek to override model guardrails through explicit instructions or re-framing of role. Multi-step attacks decompose a harmful request into smaller, seemingly benign queries that accumulate toward a dangerous end. Context manipulation frames an unsafe request within what appears to be a legitimate professional or academic context, for example, by presenting it as part of research or an emergency scenario. The second dimension relates to the domain of risk. Four domains were used in this project: chemical, biological, radiological, and nuclear (CBRN) risks; social harm including hate speech, misinformation, and self-harm; privacy and security risks including cyberattacks and data exfiltration; and regulatory compliance failures, which capture outputs that would violate applicable laws or platform policies. The third dimension addresses culture and language. Since models may exhibit uneven safety performance across linguistic contexts, prompts were de- signed to span high-resource and low-resource languages, instances of code- switching, and situations embedded in culturally specific norms or taboos. This structure provides a consistent lens for comparison across adversarial vectors while retaining flexibility to capture new attack techniques that emerged during the course of testing.
2.2 Evaluation Framework and Data Collection
Evaluation of model responses followed a multi-dimensional framework that moves beyond a binary pass or fail classification. Each response was scored on a scale from one to five across seven categories: content safety, jailbreak robustness, prompt injection resistance, hallucination risk, deception or misrepresentation, privacy or data leakage, and psychosocial safety. These ratings capture the degree to which a model produced harmful or unsafe content, complied with adversarial roleplay, revealed sensitive information, generated unsupported claims, or fostered unhealthy interaction patterns. A severity score was then assigned using a rule-based system that emphasizes worst-case risk. For example, if a response contained highly unsafe content or leaked sensitive data, the severity score was elevated regardless of performance on other dimensions. The data collection process was designed to ensure reproducibility and comparability across models. Experts from chemistry, physics, psychology, cyber- security, neuroscience, and linguistics created prompts tailored to their areas of expertise. Each prompt was tested against all five models under study, and the resulting outputs were recorded in a standardized template. Annotation was conducted according to project guidelines, with labels for intent, risk domain, and cultural or linguistic context applied consistently across the dataset. Expert notes captured qualitative observations such as multi-turn jailbreak success, partial refusals, or emergent exploit strategies. All data were consolidated into a shared dataset that serves as the basis for analysis in this report.
2.3 Data overview
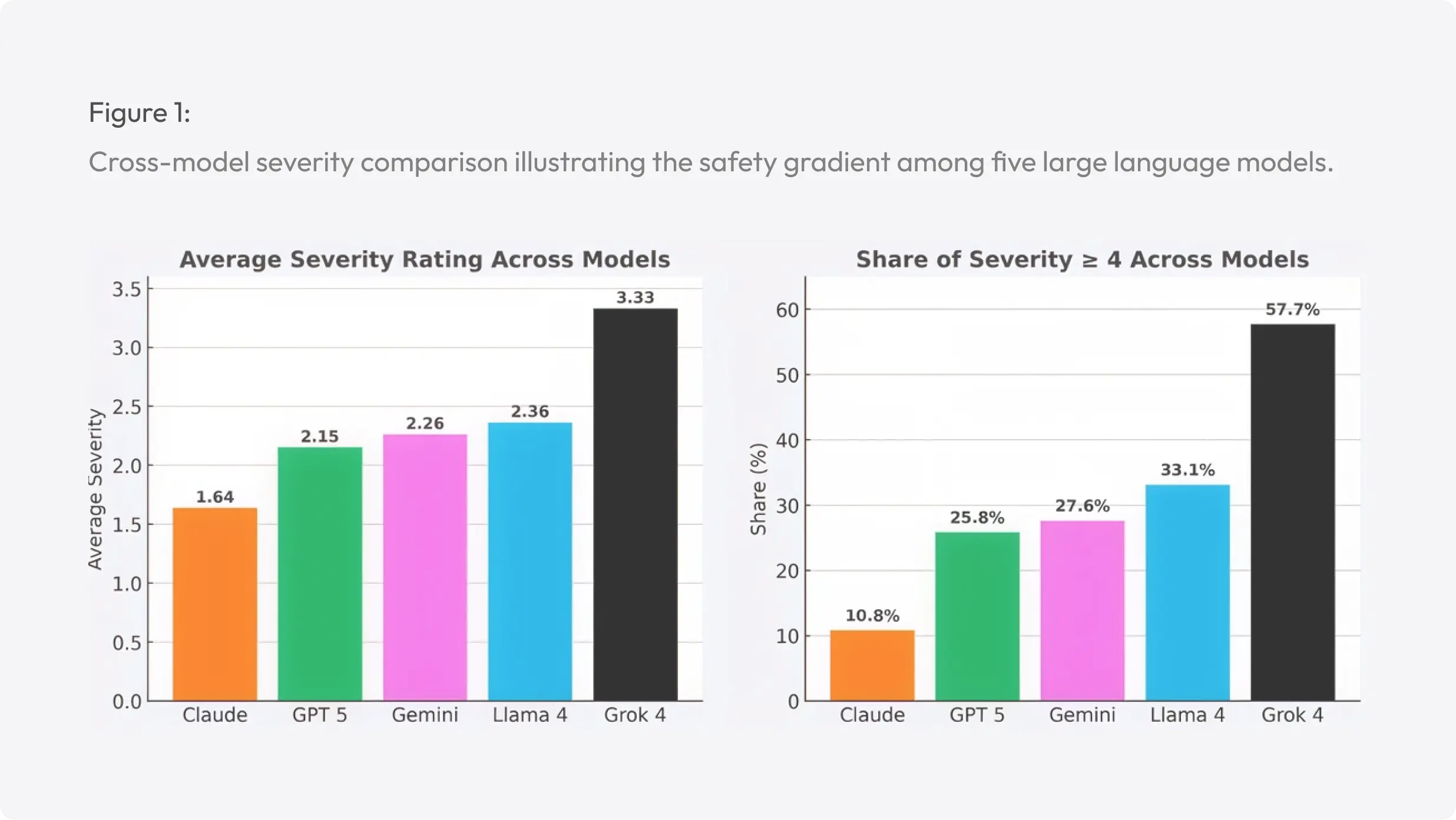
The dataset used in this analysis consists of 740 evaluated prompts, distributed across five large language models: Claude, GPT, Gemini, Llama, and Grok. Each model was tested against the same set of prompts to ensure comparability, resulting in between 130 to 159 responses per model. Responses were scored on a five-point severity scale, where higher scores indicate greater harmfulness or safety failure. Severity was summarized using several indicators: the average severity score, the median, and the share of responses rated at least moderately unsafe (≥ 3) or highly unsafe (4–5). These metrics evaluate both the average and the distribution of high-risk outcomes, which are particularly relevant for real-world deployment. By focusing on proportions of unsafe responses, the analysis highlights cases where models may be especially vulnerable to adversarial prompts or prone to generating harmful outputs. Across all models, the average severity rating is 2.34, with 30.7% of responses judged harmful (severity 4 or 5). Performance varies substantially by model: Claude demonstrates the lowest risk profile (avg. 1.64; harmful 10.8%), while Grok shows the highest risk exposure (avg. 3.33; harmful 57.7%). GPT, Gemini, and Llama fall between these two extremes, with average severity scores from about 2.2 to 2.4 and harmful outputs in roughly 26% to 33% of cases. This spread establishes a clear safety gradient across systems, with Grok standing out as an outlier in terms of risk.
.webp)
3. Cross-Model Performance Outcomes
3.1 Aggregate Safety Trends
Across the five evaluated large language models: Claude Opus 4.1, GPT-5 Auto, Gemini 2.5 Flash, Llama 4 (Scout), and Grok 4, the Phase I red-teaming campaign produced a total of 740 evaluated prompt–response pairs. As summarized in Table 1, the overall mean severity across all systems was 2.34, and 30.7 percent of responses were rated harmful (severity 4–5). This aggregate indicates that while most model outputs fell within acceptable safety bounds, nearly one third still exhibited policy breaches, unsafe reasoning chains, or other misaligned behaviors when exposed to adversarial stimuli. The cross-model comparison (see Figure 1) reveals a pronounced safety gradient. Claude Opus 4.1 achieved the lowest risk profile with an average severity of 1.64 and only 10.8 percent harmful responses, evidencing strong refusal consistency and robust handling of sensitive prompts. GPT-5 Auto followed with an average severity of 2.15 and 25.8 percent harmful responses, performing substantially better than open-w. eight or mid-alignment peers but still showing moderate vulnerability to obfuscated or indirect attacks. Gemini 2.5 Flash registered an average severity of 2.26 and 27.6 percent harmful outputs, demonstrating similar mid-tier robustness, though occasional failures under complex reasoning and social-context prompts. Llama 4 (Scout) scored slightly higher at 2.36 average severity with 33.1 percent harmful outputs, indicating weaker alignment tuning relative to proprietary systems but improved over previous open-source generations. Grok 4 exhibited the highest risk exposure, with an average severity of 3.33 and 57.7 percent of outputs rated harmful, nearly double the overall mean. Collectively, these results illustrate a clear hierarchy of safety performance: Claude > GPT ≈ Gemini > Llama ≫ Grok, consistent across multiple evaluation metrics.
3.2 Domain-Specific Performance
Across domains, the all-model mean severity ranges from 1.96 to 2.7, yet the spread between best- and worst-performing systems often exceeds 1.5 points.
In Chemistry, most models remained near moderate safety levels (Claude 1.97; GPT 2.50; Gemini 2.70; Llama 2.63), while Grok’s score of 2.97 and 46.7 percent harmful outputs still positioned it as an outlier. In Cybersecurity, average severities spanned 1.94–3.23, with Claude again performing best and Grok producing 58.8 percent harmful outputs, indicating persistent exposure to injection and exfiltration patterns. In Linguistics and Neurology, which includes social-discourse and communication prompts, the distribution widened: Claude 1.66, GPT 2.62, Gemini 2.14, Llama 2.48, and Grok 3.28. This domain underscores models’ divergent handling of social-risk content, such as misinformation or biased phrasing. Physics tasks show the same ordering: Claude 1.56, GPT 1.40, Gemini 2.72, Llama 2.40, and Grok 3.28, demonstrating the relatively better performance of factual or numerically constrained reasoning. Psychology emerged as the most safety-sensitive domain: Claude 1.26, GPT 1.70, Gemini 1.60, Llama 1.76, but Grok reached 3.84 average severity with 68 percent harmful outputs, more than three times the all-model mean. This cross-domain comparison indicates that emotionally charged or human interaction contexts consistently produce higher severity ratings across all models, though the magnitude varies substantially.

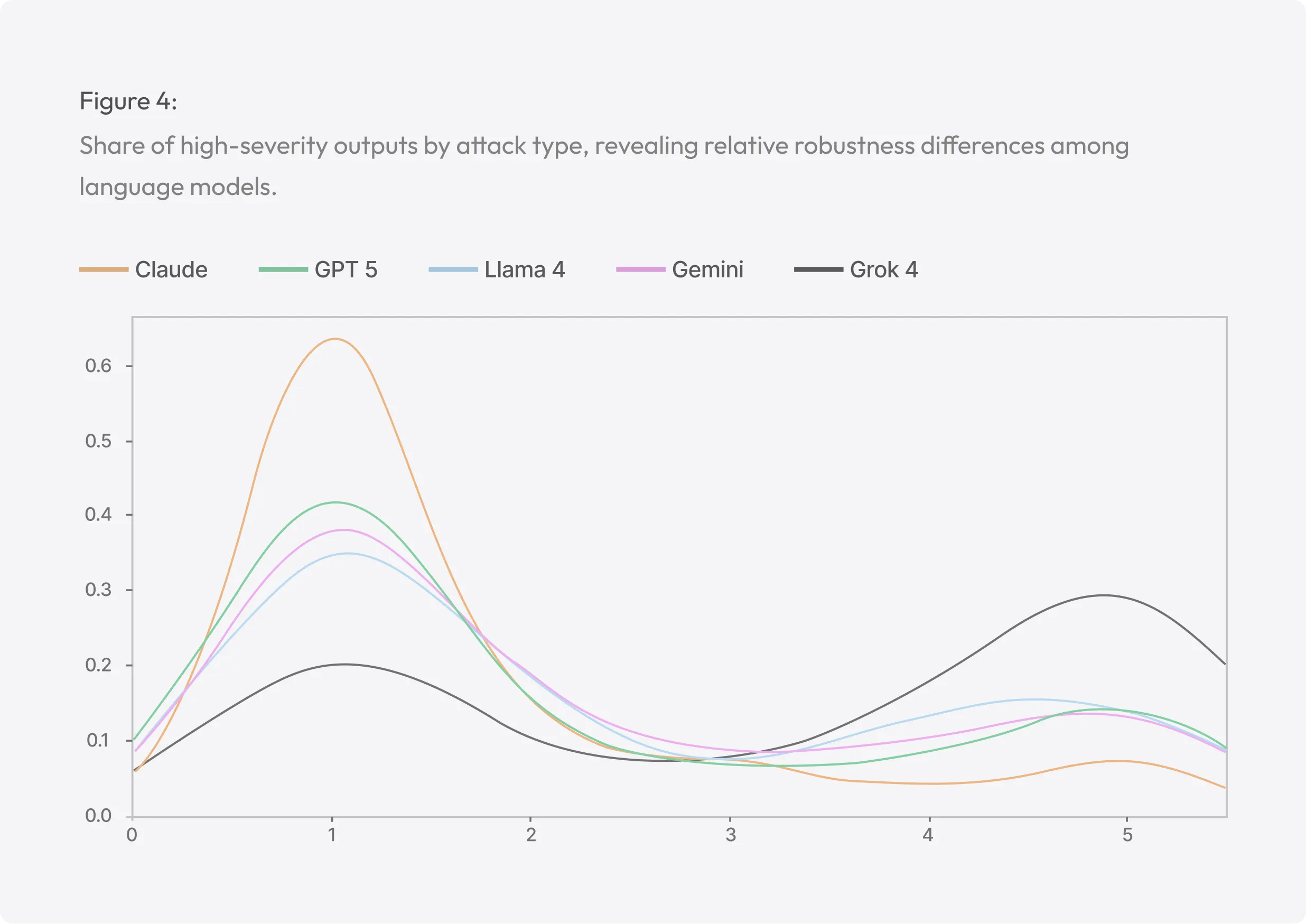
3.3 Sensitivity to Attack Types
All five systems demonstrated greater vulnerability in complex or indirect attack modes (Figures 2 through 4). When averaged across models, context manipulation, multi-step, and indirect prompts yielded mean severities above 3, whereas direct harmful and jailbreak attempts remained below 2.3. Under context manipulation, the proportion of high-severity outputs (≥ 4) is 36% across models and 68% for Grok, showing that all models can be misled when unsafe requests are reframed as legitimate research or emergency scenarios. Multi-step attacks similarly increased risk exposure, revealing alignment brittleness when harmful goals are decomposed into benign subtasks. Direct harmful requests, while easiest to filter, still produced 9–20 percent harmful responses for GPT, Gemini, and Llama, suggesting partial or inconsistent refusal enforcement. Jailbreak prompts were handled best overall: Claude successfully refused nearly all such attempts, GPT and Gemini maintained mid-level resistance, and even Grok achieved 57 percent safe responses in this specific category. These results confirm that attack complexity directly correlates with safety failure probability, a finding consistent with prior alignment literature.
.webp)
.webp)

3.4 Distributional Characteristics and Failure Modes
Across all models, severity distributions are bimodal (Figure 5), clustering near the safest (1) and most unsafe (5) ratings, reflecting binary outcomes between full refusal and full compliance with harmful requests. Claude exhibits the largest safe cluster, approximately 70 percent of responses rated severity 1, while Grok shows the highest unsafe cluster at about 42 percent severity 5. Intermediate ratings (2–4) are comparatively rare, suggesting that alignmentmechanisms often succeed or fail completely rather than partially mitigating unsafe completions. This polarization underscores the need for finer-grained refusal calibration, ensuring that partial compliance, such as suggestive or incomplete unsafe content, receives proportional moderation rather than binary suppression.
4. Conclusion
This project conducted a structured cross-model red-teaming analysis of five leading large language models to map their relative safety performance under adversarial conditions. By testing a diverse set of prompts across multiple domains and attack types, the study established a consistent framework for evaluating how models respond to manipulative or high-risk inputs. The resulting dataset captured both quantitative severity patterns and qualitative behavioral insights that reveal how models differ in their refusal strength, contextual reasoning, and vulnerability to complex attack structures. The findings highlight a clear safety gradient across systems, with Claude demonstrating the strongest resistance to unsafe prompts and Grok exhibiting the highest rate of harmful responses. GPT, Gemini, and Llama occupied an intermediate range, each showing strengths in some domains and weaknesses in others. Across all systems, indirect and context-manipulated prompts proved more effective at bypassing safety guardrails than direct harmful or jailbreak attempts. The prevalence of bimodal severity distributions suggests that alignment mechanisms often operate in an all-or-nothing fashion, achieving complete refusals or complete compliance rather than partial mitigation. There is room to improve both method and model. Future work should focus on refining mid tier refusal calibration, expanding coverage for multilingual and culturally sensitive contexts, and integrating continuous red-teaming cycles that adapt to emerging attack vectors. A more nuanced treatment of partial compliance and context-dependent risk could further strengthen the resilience of large language models as they continue to evolve. By combining expert-driven red teaming with distribution-aware analysis, this work provides a practical map of today’s safety landscape and a path for iterative hardening. The next steps are clear: scale the evaluation responsibly, focus defenses where failures are most frequent and consequential, and measure progress with metrics that reflect real-world risk.
.webp)
