Elevating enterprise conversational AI with micro1's evaluation framework
To increase the intelligence of a conversational agent, micro1 designed and implemented a custom continuous evaluation program by leveraging top human experts who exposed where the agent was weak and provided targeted training data accordingly.
%20(1).png)
%20(1).png)
.avif)
.svg)
Deploy customized AI agents for your use case
Challenge
An enterprise deploying an agentic conversational system faced significant challenges in measuring and improving its conversational performance. Traditional automated benchmarks and static evaluations were insufficient to determine whether the system was trusted by professionals, handled nuanced dialogue effectively, or could guide meaningful product improvements. The company lacked a reliable mechanism to quantify conversational quality and inform iterative refinements, hindering adoption, reliability, and overall usage.
Approach
micro1 designed and implemented a continuous human evaluation program tailored to the enterprise’s agent, combining structured measurement, expert feedback, and a closed-loop improvement cycle.
Our Process
Human-in-the-Loop Evaluation
Real professionals across diverse fields (e.g., engineering, business, psychology, research, sales) conducted actual conversations with the AI system, providing rich, real-world assessment data.
Expert Scoring Across Multiple Dimensions
Conversations were scored along 12 structured dimensions including contextual understanding, follow-up quality, domain accuracy, and conversational flow ensuring depth and precision in evaluation.
Quantitative & Qualitative Feedback Capture
Each interaction produced both numeric metrics and detailed expert insights to surface actionable patterns rather than just surface scores.
Continuous Improvement
micro1 established a weekly analysis cadence:
Expert conversations generated fresh evaluation data.
Evaluations were systematically analyzed to identify recurring failure modes and improvement drivers.
These insights informed direct product and system adjustments.
Updated versions of the agent were re-evaluated in a closed loop, embedding learning into future releases.
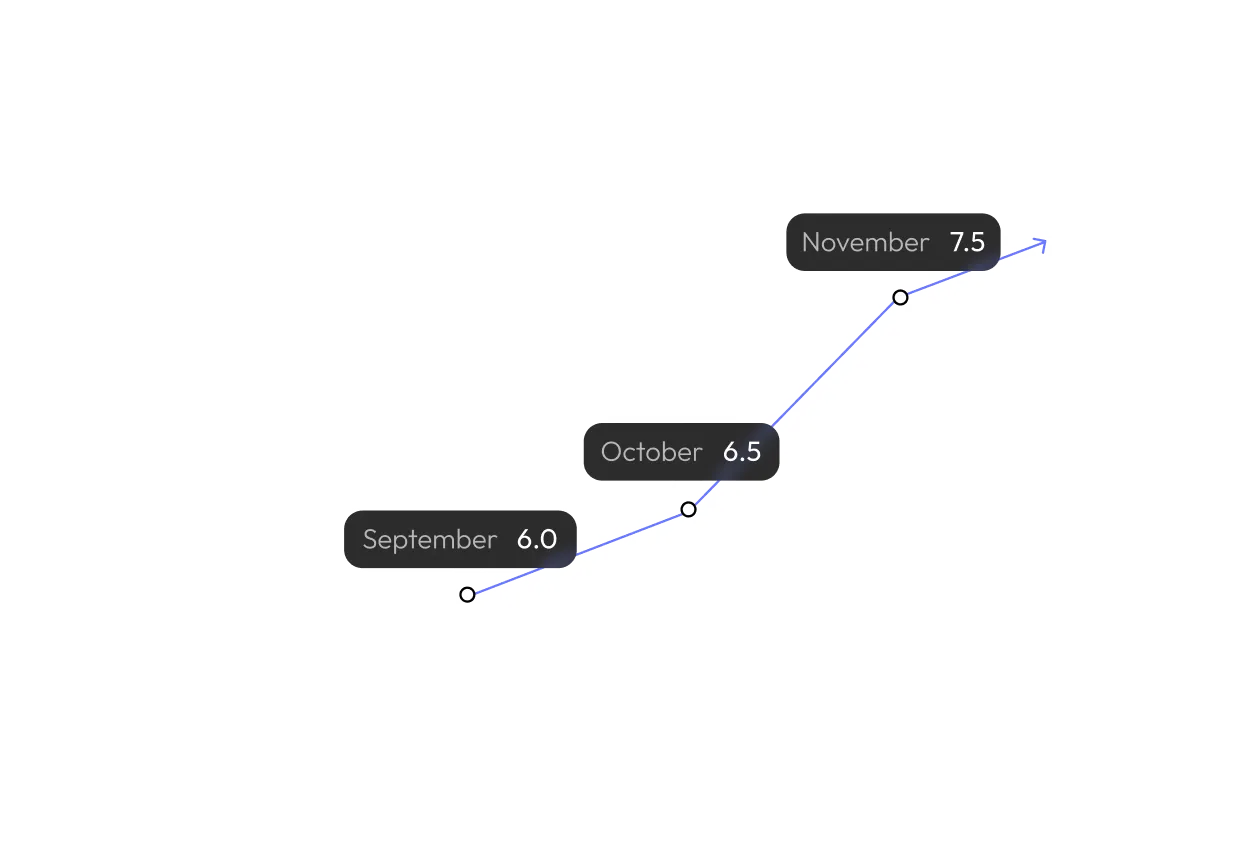
Outcome
The structured, human-driven evaluation and improvement process produced measurable gains in both perception and performance:
83% Trust Rate among domain experts evaluating the AI agent, demonstrating strong confidence in the system’s responses and behavior.
25% Improvement in Perceived Intelligence over eight weeks (from 6.0 → 7.5 on a 10-point scale), showing tangible progress in how professionals judged the agent’s conversational capability.
Identified Follow-Up Quality as the Primary Driver of perceived intelligence, directly shaping the product roadmap for conversational enhancement.
Delivered a Repeatable Framework for continuously improving AI conversational performance, enabling the enterprise to operationalize feedback rather than rely on static benchmarks.
Why This Worked
This deployment stands apart from traditional evaluation efforts for three main reasons:
Real Experts, Real Conversations
Unlike synthetic or benchmark-only evaluations, domain professionals engaged meaningfully with the AI, ensuring feedback reflected real expectations and real failure modes.
Multidimensional Scoring
By looking at 12 conversational dimensions, micro1 turned subjective impressions into actionable, measurable drivers of improvement.
Operational Feedback Loop
Weekly analysis and iteration anchored improvements in data rather than guesswork, creating a self-reinforcing cycle of performance gains.
Conclusion
By embedding structured human evaluation deeply into the agent development lifecycle, micro1 helped this enterprise build a more trustworthy, intelligent, and continually improving agentic conversational system, aligning performance with professional user expectations and accelerating adoption across internal stakeholders.
.webp)
