GPT-5.5
78.5%
Back
Realm: Pathology-report reasoning benchmark
An evaluation of frontier models on extracting pathology-report facts, preserving diagnostic limits, and avoiding unsupported clinical escalation.
Mean score
.png)
.png)
%20(1).webp)
What this benchmark measures
Realm Medical-Reasoning tests one job: read a real anatomic-pathology report and produce a faithful structured interpretation. Success is defined narrowly and deliberately — the agent must (1) extract report facts exactly as stated, (2) preserve the diagnostic limits of the specimen, and (3) avoid unsupported clinical escalation — naming treatments, stages, or biomarkers the report does not support. Every finding below ties back to those three axes.
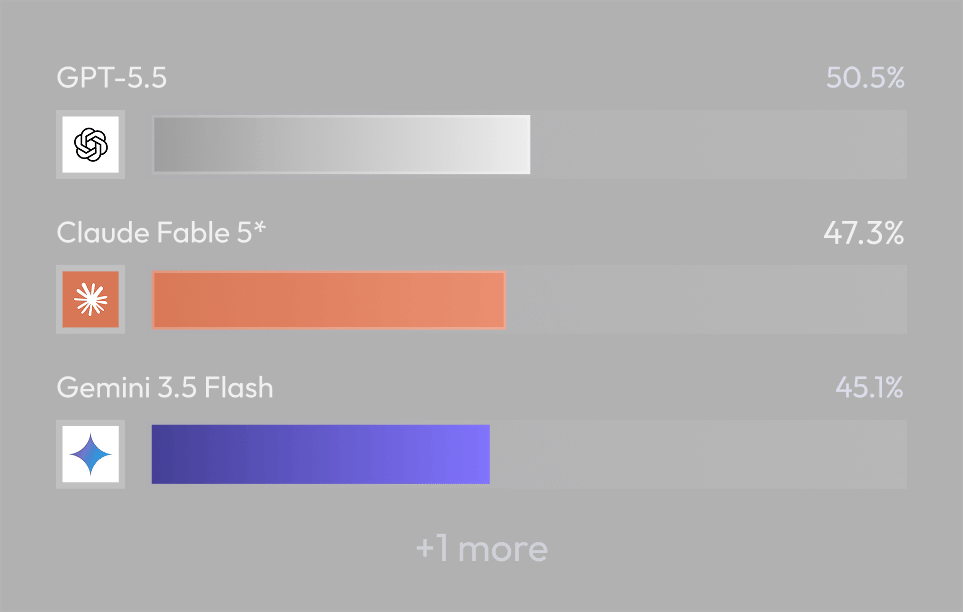
Model scoreboard
We ran a dataset of expert-authored pathology tasks against three frontier models, three independent rollouts each. Scores are mean verifier reward (0–1), where reward is the share of rubric weight a model earns on a task, averaged across its rollouts and then across the benchmark.
Mean verifier reward across all datasets (three rollouts per task). Bars are scaled to 100%.
Headline findings
Three findings shape how these results should be read. Each is stated in plain terms first, then unpacked in its own section below.
1
Opus leads, and GPT-5.5 and Gemini are a near-tie behind it — but the tie hides different error profiles.
Opus 4.8 is the clear top model at 82.6%, roughly 6 points ahead of GPT-5.5 (76.3%) and Gemini 3.5 Flash (75.7%) on average per-task reward. GPT-5.5 and Gemini finish within 0.6 points of each other, so on the headline number they are effectively tied. That tie is misleading: the two models lose reward in different places. GPT-5.5’s misses tend to be quiet over-confidence — it smooths a caveat away or recalculates a stage the report already gave.
2
The benchmark rewards restraint as much as it rewards extraction.
A pathology report has hard edges: a 4 mm biopsy fragment is not a tumor size, a nodal specimen alone cannot carry an overall stage, a “suspicious” cytology is not a cancer diagnosis. Models lose the most reward when they cross those edges — supplying a stage, biomarker, or treatment the specimen does not support. Plainly: the failures are less about getting facts wrong and more about saying more than the report allows. This is the single thread that runs through every failure mode in this report.
3
Reading the agent’s trajectory — not just its score — is what reveals why two answers diverge.
Scores alone tell you Opus beat GPT-5.5 on a marrow case by 31 points. Reading the two trajectories tells you why: on the report_33_MDS task, the weaker run reached the same diagnosis but stated it as settled, dropping the unresolved hypoplastic-MDS-versus-aplastic-anemia differential the rubric required. The result of doing trajectory review across all 50 tasks is concrete and actionable: longer runs do not buy accuracy. The most over-produced traces — 10–20 tool calls, repeated planning loops — were frequently the lowest-scoring, because the extra steps were spent escalating past the report rather than reading it more carefully. The highest rewards came from short, disciplined runs (often 2–3 tool calls) that extracted, stated limits, and stopped.
Benchmark overview
Each task drops a model into a fresh sandbox with one or more real anatomic-pathology reports (de-identified) and a generic toolkit: a shell, file read/write, a code editor, and web search. The agent extracts the report — typically with pdftotext or a Python library — analyzes it, and writes a single structured interpretation to response.md. An LLM judge then scores that answer against an expert-authored rubric of weighted criteria. The run reward is earned weight over total positive weight, clamped to [0, 1].
Task taxonomy
The datasets are drawn from routine diagnostic pathology and span the organ systems and specimen types a working service sees. The mix is intentional: most tasks are single-report interpretations, but a meaningful fraction are multi-report cases (marrow workups combining myelogram, flow cytometry, biopsy, and cytogenetics) that require reconciling several modalities into one read.
Distribution across the 50-task set. Counts are approximate groupings; some multi-organ cases are filed under their dominant specimen. 41 tasks are single-report; 9 are multi-report integrations.
Performance by clinical domain
Reward also varies by specimen type. The table below reports mean reward per model across the clinical domains in the set. The ordering tracks how much restraint a domain demands: domains where the specimen is partial or the call is a category rather than a diagnosis (breast nodal specimens, thyroid cytology) sit lowest, because they punish inference and escalation most heavily.
Performance summary
Pairwise per-task reward differences make the ordering precise.
Average and median per-task reward differences. Opus separates cleanly from both; GPT-5.5 and Gemini are within noise of each other on aggregate.
Hardest tasks: where every model struggled
These are the lowest-reward tasks in the benchmark. The pattern is consistent with finding 2: each one punishes saying more than the specimen supports. The “anchor missed” column is the single rubric criterion most responsible for lost reward — read it as the thing the report did not let you say.
Largest model spreads: where behavior separated most
These tasks produced the widest gap between the strongest and weakest model on the same problem — the most informative cases for understanding what distinguishes a good pathology read from a weak one.
Highest per-task spread between best and weakest model. These tasks anchor the trajectory deep-dives.
Where models lose reward
We categorized every failed rubric criterion across the trajectory set into recurring failure modes, then counted how often each occurs. The frequencies below are the share of all failed criteria that fall into each mode (a criterion can touch more than one). Every mode is grounded in a complete example — prompt context, the exact rubric criterion, the model’s response, the judge’s verdict, and the judge’s justification — so the failure is legible rather than asserted.
Computed multiple failed criteria in the trajectory set. “Clinical over-reach” and “Unsupported inference” together account for the largest block of lost reward — both are forms of saying more than the report supports.
Clinical over-reach (≈28% of failures)
What it means: The task asks for a report interpretation; the model answers like a treating clinician — naming a surgery, drug regimen, surveillance interval, or therapy the report neither contains nor requests.
Why this is a clean over-reach: The specimen is a tissue diagnosis: “active chronic gastritis, H. pylori present.” Nothing in the report calls for therapy, and the prompt asks for an interpretation. Prescribing a named, dosed, multi-drug antibiotic regimen is purely a treating-clinician act — the model has stepped from describing the slide to managing the patient. Unlike a borderline case where a recommendation might read as reasonable clinical context, there is no defensible reading in which naming “bismuth, tetracycline, and metronidazole for 14 days” belongs in a pathology read.
It is not a single-model quirk: The same guardrail caught the strongest model on the same task: Opus 4.8 (reward 90%) lost the criterion for recommending both bismuth quadruple therapy and clarithromycin triple therapy and naming tetracycline, metronidazole, clarithromycin, and amoxicillin. When even the top run on a task over-reaches into a drug regimen, the failure is structural — a default pull toward being helpful past the edge of the document — rather than a weakness specific to one model. The same pattern recurs across domains: naming Mohs surgery off a punch-biopsy basal cell carcinoma (report_2605653), prescribing steroid therapy for an organizing-pneumonia pattern that is not even a confirmed clinical diagnosis (report_2605435), and listing endocrine agents, letrozole, anastrozole, exemestane, off a breast core biopsy (report_2605225).
Unsupported inference (≈15% of failed criteria)
What it means: A limited specimen is used to infer something it cannot establish — an overall stage, a missing biomarker, a primary tumor type, or a final subtype. This is the mirror image of over-reach: instead of adding management, the model adds findings.
This is the hardest task in the benchmark (mean 51.9%) precisely because the right answer is mostly about what not to say. The strongest run on the same task (GPT-5.5, 81%) named the same limitations explicitly — “no primary specimen, so stage and receptor status cannot be assigned here” — and stopped.
Collapsed uncertainty (≈11% of failed criteria)
What it means: The report deliberately leaves a question open — an unresolved differential, a discordance between modalities, a missing test — and the model resolves it too decisively. The clearest case is the marrow workup that anchors finding 3.
The winning Opus run (92%) reached the same leading diagnosis but framed the core–aspirate discordance as a substrate problem rather than a contradiction, and kept the aplastic-anemia differential and the missing PNH-clone test in view. Same destination, different epistemics — and the benchmark rewards the epistemics.
Cross-report reconciliation
What it means: multi-report tasks are not just extraction — the answer has to say how morphology, flow, cytogenetics, and immunostains agree or remain in tension, and which modality should dominate. Weaker traces list each modality’s findings without naming the synthesis. Opus is strongest here; the AML-remission case (report_34_AML_remission) is the cleanest illustration: the rubric required stating that a 0% morphologic blast count and a 0.20% flow MRD result are not discordant — flow is simply more sensitive — and the weak Gemini run framed them as a “clear discrepancy,” inverting the intended reading.
Trajectory deep-dives
Each deep-dive contrasts a low-scoring and a high-scoring trace on the same task. For each, we give enough context to read the task cold — the prompt, the rubric anchor in play, the verdict, and the judge’s justification — plus the high-level reason the scores diverged. These are the cases that make finding 3 concrete: the difference is rarely extraction and almost always interpretation.
Deep-dive 1 — report_33_MDS · spread 31.0 pts
What it means: A four-modality marrow workup where the controlling skill is preserving an unresolvable differential rather than committing to a diagnosis.
Why it diverged: Both runs used the same number of tools and reached the same leading diagnosis. The 31-point gap is entirely about whether the answer held the differential open. Trajectory length explained nothing; epistemic discipline explained everything.
Deep-dive 2 — report_2605510 · spread 29.9 pts
What it means: A partial-nephrectomy renal-tumor report with an internal staging contradiction: the report assigns pT1b but documents tumor in perirenal fat (which defines pT3a).
Why it diverged: The weak run had the right instinct (something is off with the stage) but stopped at a vague flag. The benchmark rewards naming the discrepancy precisely. Here the shorter trace (2 tool calls) scored far higher than the longer one — restraint plus precision, not effort.
Deep-dive 3 — report_2605240 · spread 29.0 pts
What it means: A benign thyroid FNA (Bethesda II). The skill under test is holding a benign call rather than over-working it.
Why it diverged: The weak run had the right instinct (something is off with the stage) but stopped at a vague flag. The benchmark rewards naming the discrepancy precisely. Here the shorter trace (2 tool calls) scored far higher than the longer one — restraint plus precision, not effort.
What this means for deploying models on pathology workflows
Realm Medical-Reasoning is hard because it is concrete: the rubric grades exact figures, preserved limits, and the absence of unsupported escalation, with no credit for sounding authoritative. Three takeaways follow, each tied back to the benchmark goal.
Extraction is largely a solved sub-task; restraint is not
All three models read messy reports, pick the right tool for each format, and produce coherent structured summaries. The reward is lost downstream — at the point where the model decides whether to stop at interpretation. Deployments should treat the extraction layer as reliable and put human review where escalation happens.
The dangerous errors are confident additions, not omissions
Clinical over-reach and unsupported inference together drive the largest block of lost reward, and both produce plausible-looking output — a named therapy, an inferred receptor status — that a hurried reviewer could accept. A reviewer should specifically check that every stage, biomarker, and recommendation in the output is actually present in the source report.
Score the trajectory, not just the answer — and don’t reward effort
Two models within 0.6 points on aggregate (GPT-5.5 and Gemini) fail for opposite reasons, and the longest, most process-heavy traces were often the weakest. Teams evaluating models for this kind of work should look at how an answer was produced, and should be suspicious of length as a proxy for care.
Loading benchmark data…
A pathology-report benchmark that tests whether agents can extract report facts, preserve diagnostic limits, and avoid unsupported clinical escalation. Scores below are mean verifier reward, averaged per model over the benchmark.
Claude Opus 4.8
77.5%
Gemini 3.5 Flash
65.2%
Headline Findings
Opus 4.8 leads
Opus 4.8 is the clear leader at 82.6%, with a +6.3 pts average task-level edge over GPT-5.5 and +6.9 pts over Gemini 3.5 Flash.
GPT-5.5 and Gemini 3.5 Flash are effectively close
GPT leads by +0.6 pts on average, but their error profiles differ more than the aggregate score suggests.
The benchmark stresses restraint as much as extraction.
The biggest recurring misses are exact quantitative anchors, avoiding management recommendations, not inferring unavailable biomarkers or stage, and preserving uncertainty across discordant modalities.
Trajectory review matters
Trajectory review matters: long planning traces and extra searches do not reliably improve outcomes when the agent crosses from pathology interpretation into guideline management.
Performance summary
The aggregate view is intentionally narrow: model reward, model deltas, and representative hard cases. Operational inventory is omitted from this report.
Pairwise Model Deltas
Average and median per-task reward differences.
| Comparison | Mean Delta | Median Delta |
|---|---|---|
 Opus 4.8
vs. Opus 4.8
vs.
 GPT-5.5 GPT-5.5
|
-0.9 pts | -2.6 pts |
Opus 4.8
vs.
 Gemini-3.5 Flash Gemini-3.5 Flash
|
+12.4 pts | +6.3 pts |
|
GPT-5.5
vs.
Gemini-3.5 Flash
|
+13.3 pts | +7.7 pts |
Model Readout
Opus wins through fewer severe misses and better boundary control. GPT and Gemini are close overall, with GPT more compact and Gemini more process-heavy.
Claude Opus 4.8
82.6%
GPT-5.5
76.3%
Gemini 3.5 Flash
75.7%
Hardest Examples
Lowest aggregate reward cases and the rubric anchor most often missed.
States the baseline risk of malignancy for Bethesda Category II as below 3%.
Reward: 61.6%
Strongest GPT-5.5
Weakest Gemini-3.5 Flash
Weakest Gemini-3.5 Flash
Largest Model Spreads
Cases where model behavior separated most sharply.
Benign thyroid FNA exposed over-calling: the weak trace preserved the Bethesda label at first, then questioned adequacy and escalated toward repeat sampling and molecular testing.
Spread: +29.0 pts
Strongest GPT-5.5
Weakest Gemini-3.5 Flash
Weakest Gemini-3.5 Flash
| Rank | Model | Average | Best | Worst | Runs |
|---|
Main Failure Modes
Trajectory Reader
Each task view contrasts a low-scoring trace with a high-scoring trace. The excerpts include verifier notes, answer text, and condensed agent steps.
Criterion Heatmap
Criterion
Description
GPT 5.5
Opus 4.8
Gemini-3.5 Flash
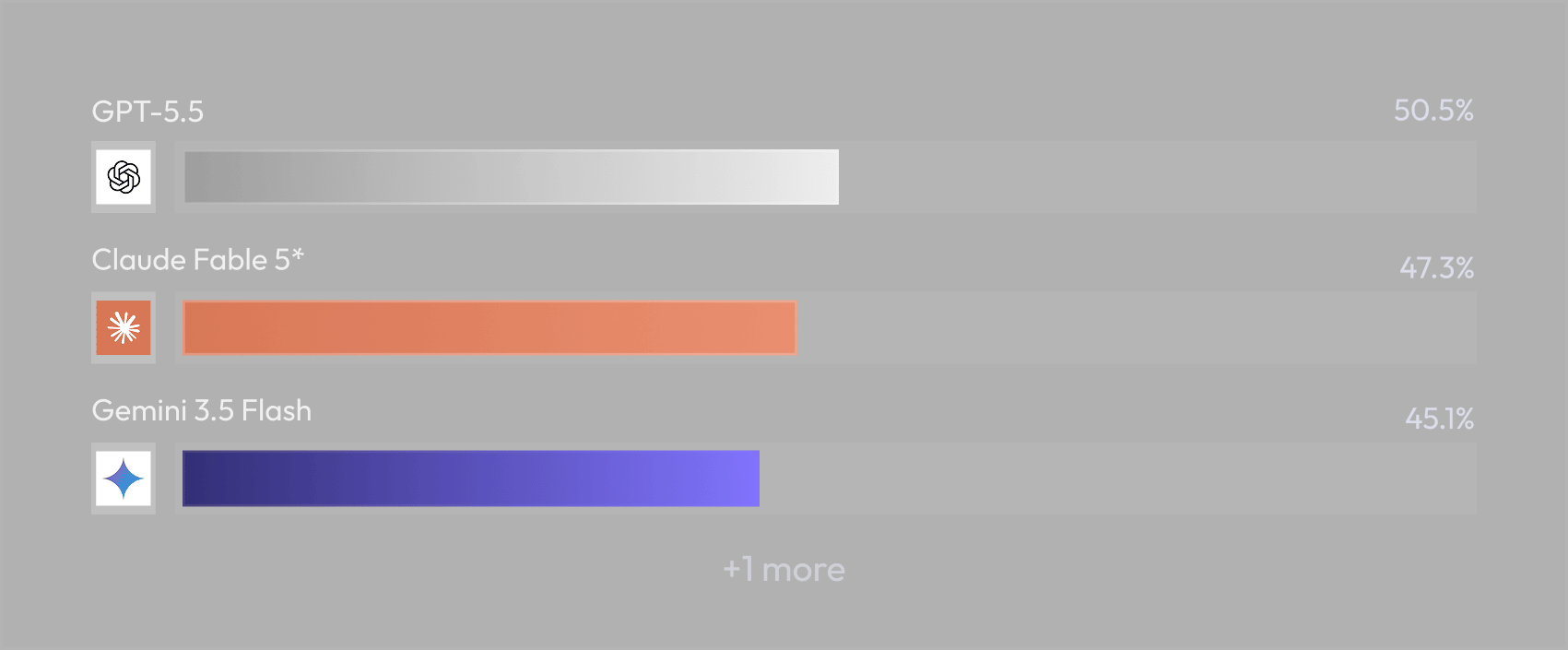
.webp)
.webp)
.webp)
.webp)
