Cortex
Evaluate, improve, and monitor AI agents with expert judgment grounded in real workflows
.webp)
.avif)
The reliability layer for agentic AI
As AI agents move into real workflows, teams need a way to evaluate performance, understand failures, improve behavior, and monitor reliability after launch
Today, most teams are still missing the basics:

Clear ways to measure agent performance

Visibility into where and why agents fail

Continuous monitoring once agents are live

Evaluations grounded in real workflows

A scalable way to translate company context into agent behavior

Expert review beyond automated evals and LLM-as-judge
How it works
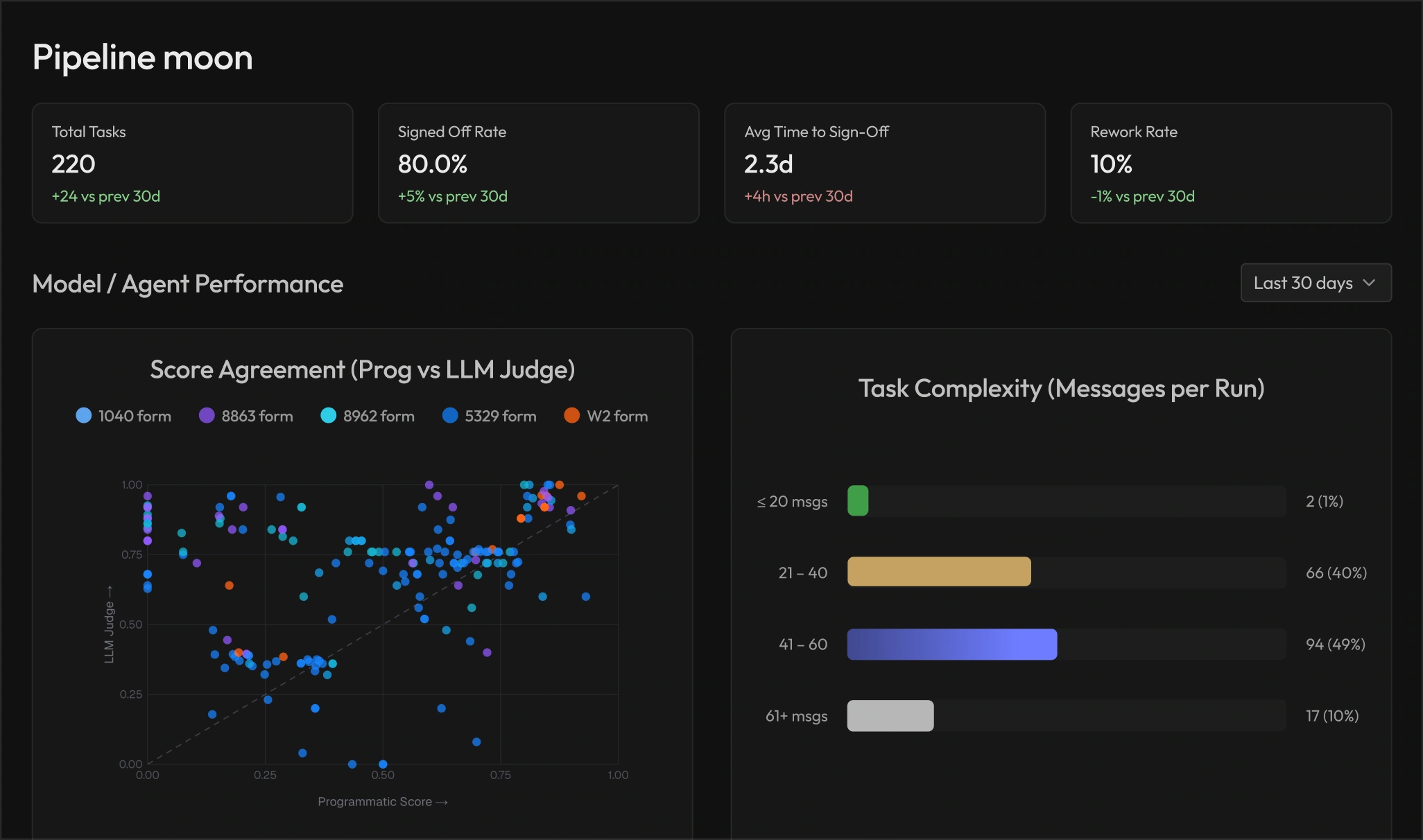
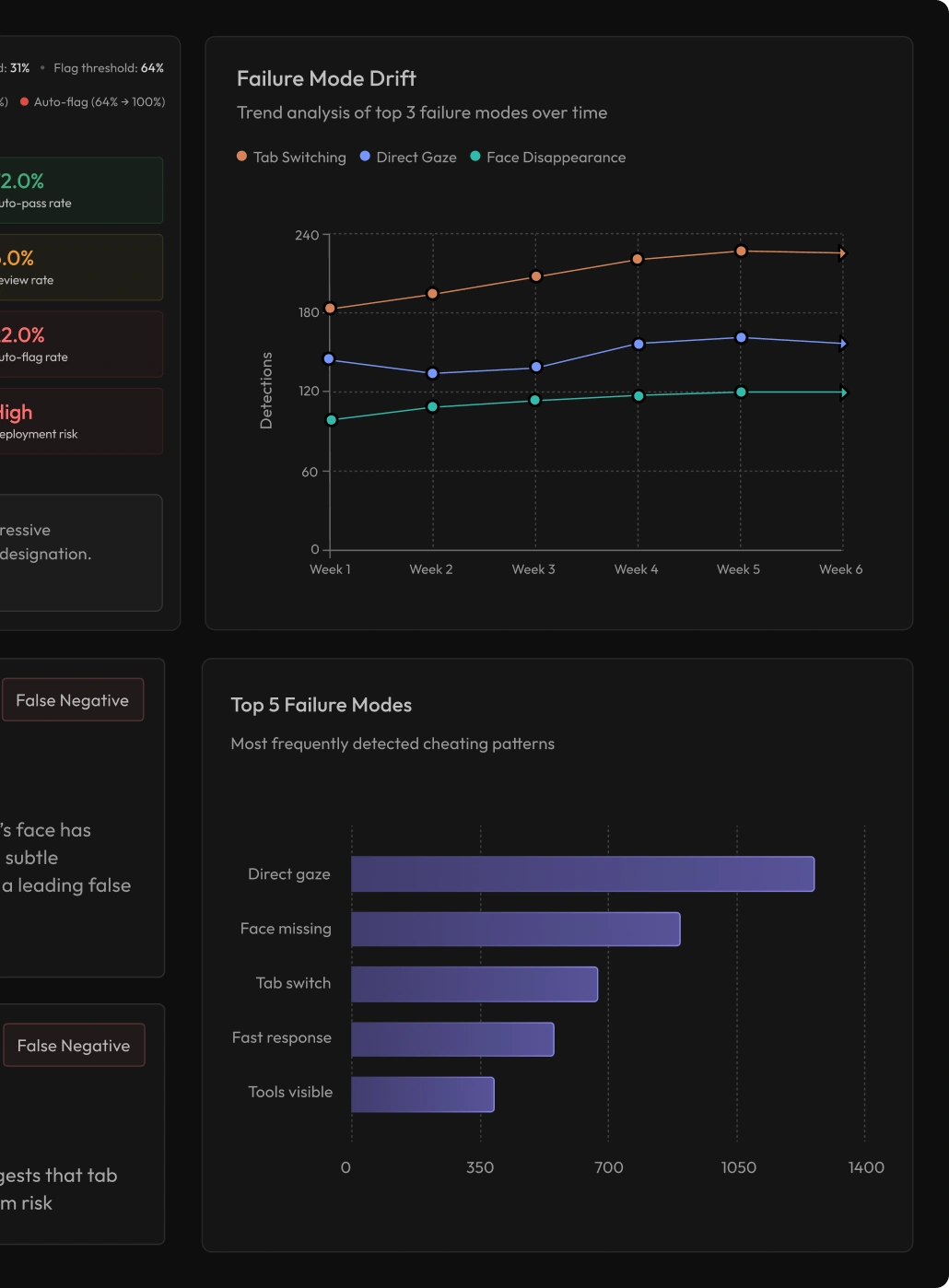
Cortex turns agent reliability into a measurable process by evaluating real workflows, diagnosing failures, creating targeted expert data, and monitoring performance
1
Workflow design
Define the agent’s task, success criteria, rubrics, and scoring approach
2
Failure diagnosis
Domain experts review agent outputs and identify where, why, when, and how the agent fails
3
Targeted training data
Produce expert feedback and improvement data tied to the highest-priority failure modes
4
Monitor reliability
Re-evaluate and track performance as models, prompts, workflows, and rules change
Impact

Faster Time to Production
Identify failure earlier, improve systems faster, and reduce iteration cycles

Clear AI Performance Visibility
See where systems fail, why, and what to fix

Greater Customer Trust
Improve consistency and accuracy in critical AI experiences

Continuous Improvement
Track performance as models and workflows change
