Back
LongExtractionBench
Seven production extraction systems on the same 225 documents, long, content-rich documents that stress extraction systems.
.png)
.png)
.webp)
.webp)



%20(1).webp)
1. Executive Summary
We evaluated seven production extraction systems on the same 225 documents: four dedicated document-extraction platforms (Reducto Deep Extract, Extend - MAX, LlamaExtract - Agentic, Datalab Extract - Balanced) plus three frontier LLMs called directly (GPT-5.5, Claude Opus 4.8, Gemini 3.1 Pro). The corpus is deliberately hard: documents average 358 pages and roughly 88,700 ground-truth fields each. Every system was run in its strongest available configuration: The frontier models were run with maximum thinking/reasoning enabled across the board, and Reducto, Extend, LlamaExtract, and Datalab Extract in their highest-accuracy extraction modes.
The headline is not a single accuracy number; it is a gap in who can finish the job at all. Results are reported along four separate dimensions, kept deliberately distinct: success performance (accuracy on completed documents), failure metrics (accepted then could not finish), incompatibility (refused up front as unsupported in kind, independent of size), and latency.
What we found
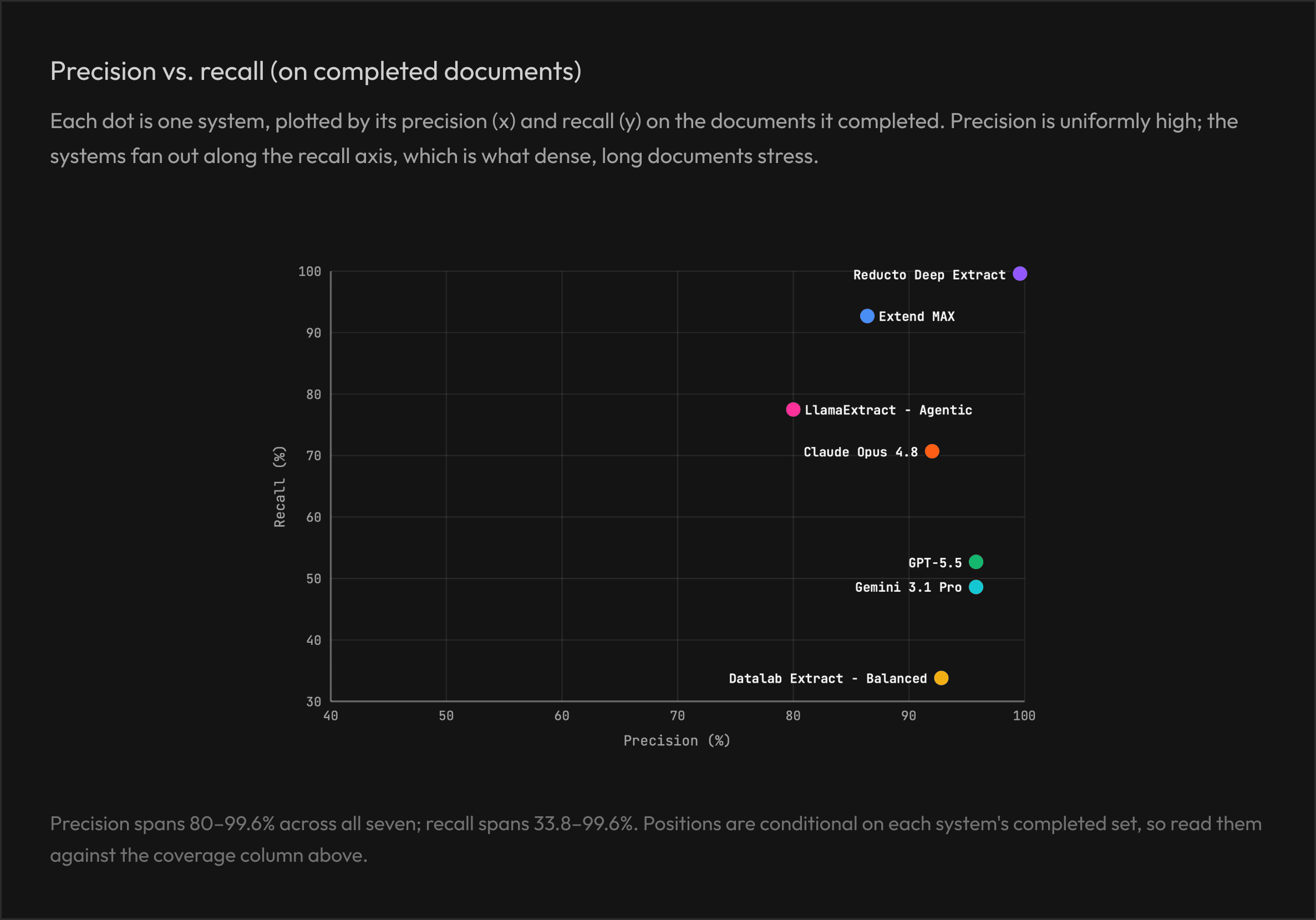
Recall is the great separator. Precision and leaf accuracy cluster high across systems; recall ranges from 49% to 99.6% and tracks completeness, exactly what long, dense documents stress.
Direct frontier LLM baselines had substantially lower completion rates on long documents. Gemini 3.1 Pro and Claude Opus 4.8 completed only 112 and 116 of 225 documents. Their high accuracy figures (96.2% and 91.7% leaf) are a conditional metric, true only on the short documents they managed to finish.
The strongest dedicated platforms beat raw frontier models on robustness and completeness. Reducto, Extend and LlamaExtract finish far more of the corpus and achieve higher recall than any frontier model.
2. Why This Benchmark Exists
Much of the highest-value work in enterprise data extraction lives in long, content-rich, table-heavy documents: statistical releases, census tabulations, financial and regulatory filings, healthcare datasets, scientific reference tables. These documents routinely run from hundreds to thousands of pages and pack tens of thousands of individual values into dense, repeating tables, and the numbers locked inside them feed real downstream workflows, from financial models to regulatory reporting to operational decisions. Extracting them is a substantial challenge: the length alone strains context windows and output limits, tabular structure has to be held together across page breaks and shifting layouts, and dropped or misread rows can quietly corrupt an entire analysis. This is exactly the environment where extraction systems degrade or fail outright the capability this benchmark measures.
The question this benchmark answers is simple: which platform performs best when the documents are dense, across accuracy, robustness, and latency, rather than on a curated simple set. We measure not just "how accurate is it when it works," but "how often does it work at all, and how does it fail when it doesn't."
3. Independence & Governance
4. How Ground Truth Was Built
Ground truth was created independently from the raw documents, without any extraction vendor or product in the loop, and was human-reviewed and reconciled before acceptance.
The candidate labels were drafted by frontier models reading each source document directly: GPT-5.5 and Claude Opus 4.7. No document-extraction product, and no OCR, parsed text, or layout from any extraction system, was part of the process. Human annotators then reconciled the disagreements between the two models and additionally reviewed a sample of the labels the models agreed on, confirming that agreement reflected correctness rather than a shared mistake, before the result was accepted as ground truth.
5. The Corpus
Documents
225
Pages / document
358
GT fields / document
≈88,700
Schema fields / document
≈44
The dataset is a mixture of short releases and documents in the thousands of pages. Density is the defining property: a few dozen schema fields expand into tens of thousands of ground-truth values per document because those fields repeat across long tables. The corpus spans government and public-sector statistics, census and demographic tabulations, labor series, financial filings and asset-backed-securities reports, healthcare and Medicare datasets, regulatory/permit filings, and scientific reference tables; it is predominantly English-language public documents.
6. How We Score
The grader is deterministic: no LLM, no fuzzy matching beyond an explicit cosmetic normalizer. Each document yields three numbers in [0, 100]:
Precision
Precision of the array rows a system returned, the fraction that match a real ground-truth row - paired by the key the grader infers for that array, not by position. Penalizes hallucinated, duplicated, or extra rows.
Recall
Recall of the ground-truth array rows, the fraction the system returned and correctly matched. Penalizes missed rows and near-duplicates that fail to match.
Leaf accuracy
Leaf accuracy of the ground-truth leaf values a system could be scored on (i.e. on correctly-matched rows), what fraction match after cosmetic normalization. This measures cell-level correctness given that a row was returned.
Row matching is key-based, never positional. For each ground-truth array the grader infers the field(s) that most uniquely identify a row, then matches predicted rows to ground-truth rows by that key. Documents are score and then averaged with equal weight.
7. Results: The Four Dimensions
7.1 Coverage: who finished the job
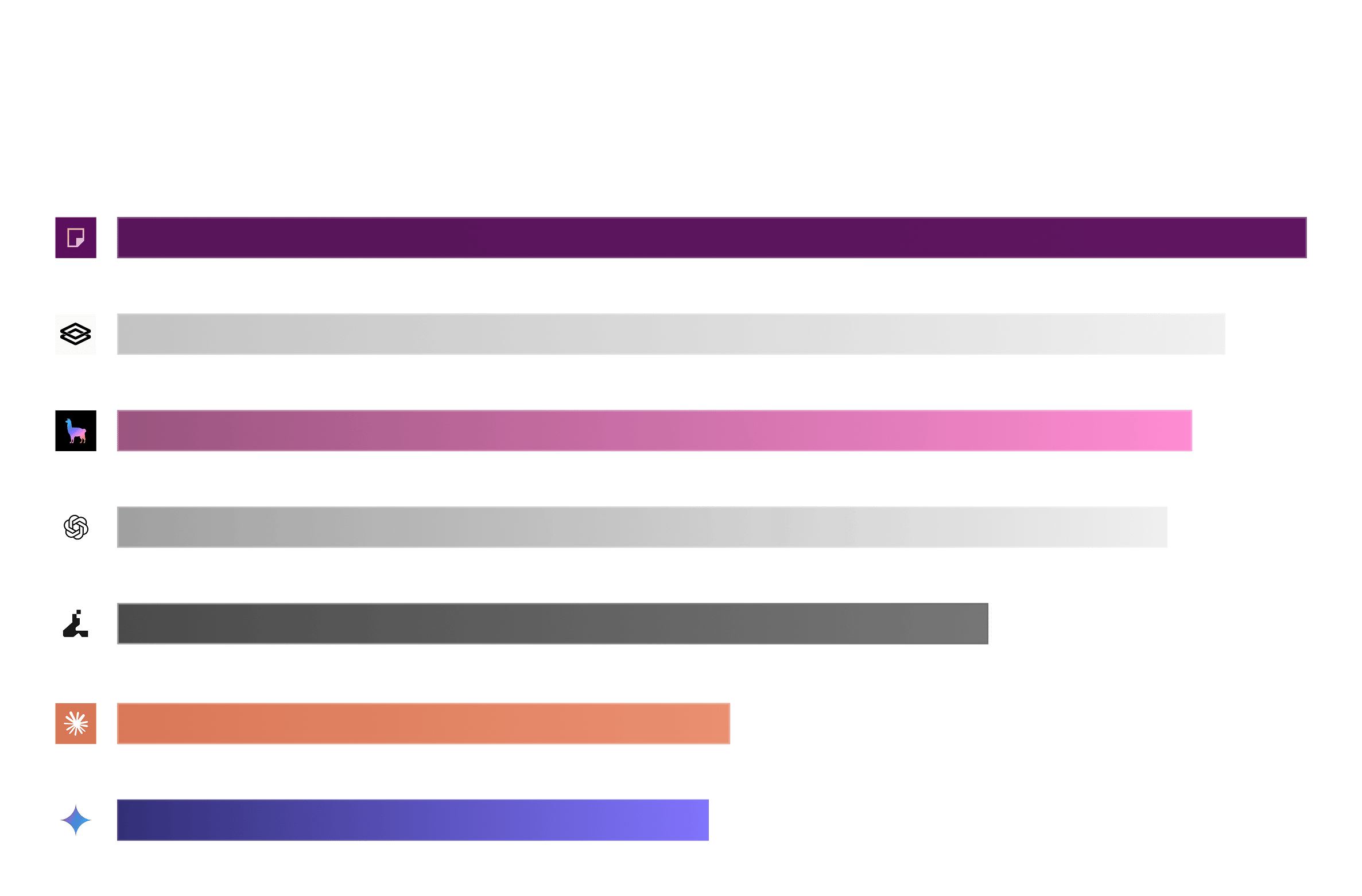
Coverage spreads across a wide range rather than splitting into neat tiers: one full-coverage system (Reducto), a cluster that finishes in the high-80s to low-90s (Extend, LlamaExtract, and GPT-5.5), Datalab Extract (Balanced) at 74%, and the two lowest coverage frontier models that fall closer to ~50%. The spread is the whole story: the documents the lower-coverage systems drop are the hard ones, so every accuracy number below must be read against this column.
7.2 Success performance: accuracy on completed documents
These figures describequality given that the system returned a result.They donotpenalize non-completion and are only interpretable jointly with coverage above.
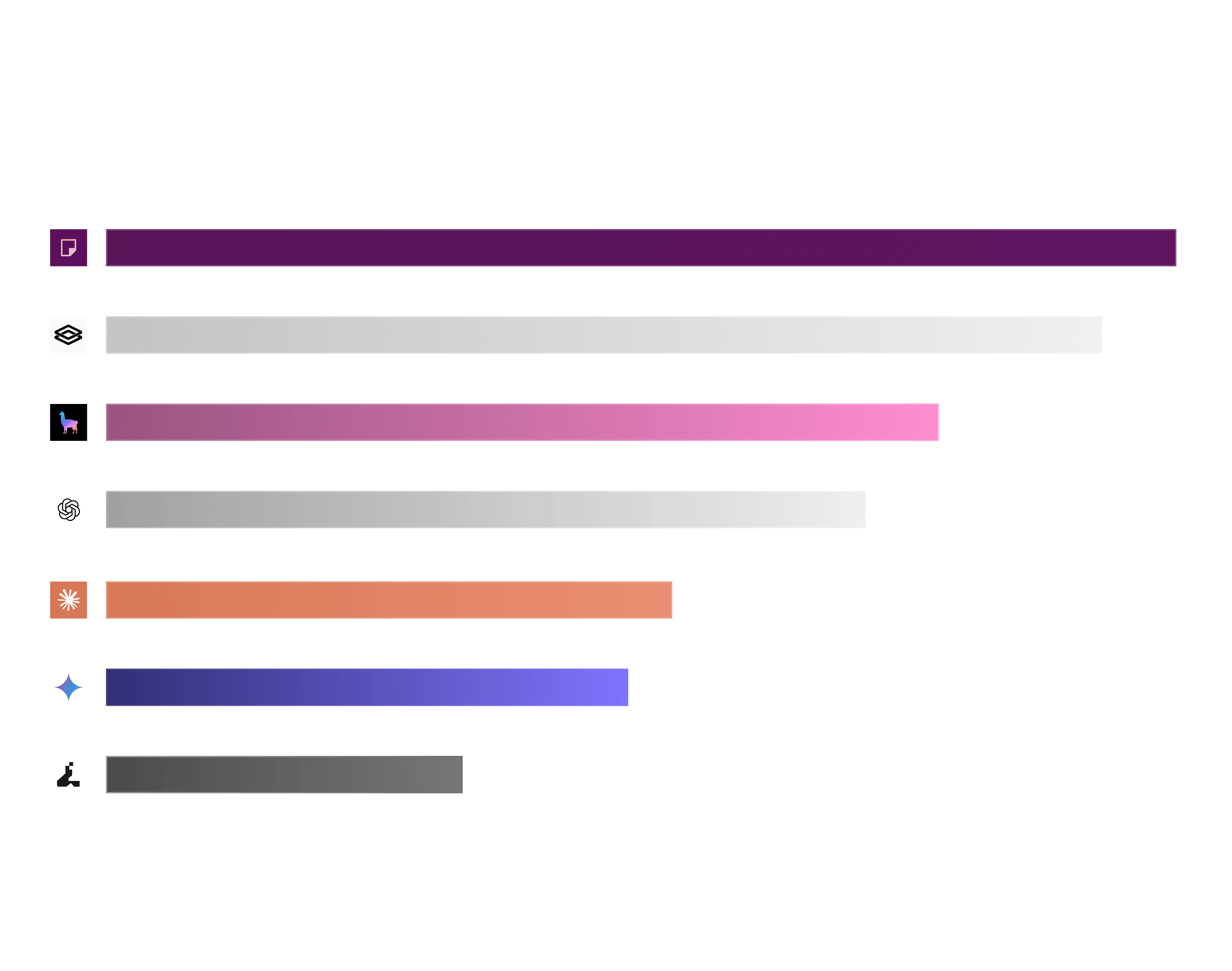
Apples-to-apples: the common-completed subset
To remove the coverage confound, all seven systems are re-scored on only the documents every system completed, the 61-document intersection. Caveat: this subset is comprised primarily of the easy/short documents the weakest systems could finish, so it understates the gap on hard documents.
Even on this easier subset, frontier-model recall sits at 74–79%, so some rows go unextracted on documents these models complete. Datalab Extract (Balanced) is lower at 64.4%. Reducto still leads recall (99.8%), and leaf accuracy is effectively a tie at the top (Reducto 98.9%, GPT-5.5 98.7%). The gap narrows on easier documents without fully closing - the main differentiator is robustness on hard documents rather than cell-level accuracy on easy ones.
7.3 Failure metrics: defeated by the document, not refused for kind
A failure is a document a system could not complete for capacity or operational reasons: output truncation, input-context overflow, or timeout.
The frontier LLMs break far more often than the strongest dedicated platforms (GPT-5.5 on 12% of the corpus, Gemini on 36%, Claude on nearly one document in two at 48%), and the mode of failure differs by model. GPT-5.5's failures are exclusively input-side: the document plus schema overruns its context window before generation begins. Claude and Gemini mostly break mid-generation, cut off by their output-token ceilings. The dedicated platforms split: Extend and LlamaExtract break only on a small slice of the longest documents (3.6% and 9.8%) and Reducto had no recorded failures in this run, while Datalab Extract (Balanced) failed on 26.2% of the corpus.
7.4 Incompatibility: refused as unsupported in kind
An incompatibility is a document a system refused up front as unsupported in kind: a malformed or non-representable schema/request rejected before processing (e.g.INVALID_ARGUMENT), independent of document size. It is conceptually distinct from a failure and we never merge the two. Crucially, a size-driven up-front rejection (context-window overflow, page cap) is a failure, not an incompatibility: the identical request on a smaller document would have been accepted.
Incompatibility is now concentrated almost entirely in Gemini: 32 documents (about one in seven) are rejected up front on documents well within its size limits, a genuine schema/request rejection, not a size problem. Extend refuses 7 on non-retryable schema grounds. Every other system refuses nothing up front.
7.5 Failure modes by category
Every document a system accepted and then could not finish, broken out by failure mode. These are failures only: up-front refusals (schema / request rejected) are incompatibilities, not failures, and are shown separately under incompatibility (7.4 above). Each row sums to that system's total failures.
The single dominant mode across frontier models is output truncation (67 documents for Claude, 66 for Gemini): asked to emit a very large structured object, the model is cut off by its output-token ceiling. These are capability limits on long documents, not accuracy mistakes, and they hit the same documents a dedicated platform processes without incident. "Input exceeds context window" bundles both token-context overflow and hard page caps (LlamaExtract and Gemini at 1,000 pages, Claude at 600): both are the same failure at root, the input document being too large for the model to take in before generation begins.
Datalab Extract (Balanced) fails differently from other systems. Its 59 failures are almost all in the rightmost column: 28 documents whose schema was too complex for the Balanced tier (a configuration/capability limit of the mode tested, not document length), 21 server-side pipeline errors, and 8 timeouts. Only 2 failures were size-driven page caps (documents beyond 7,000 pages).
7.6 Latency
These distributions are heavy-tailed, so the mean and p50 diverge sharply. Read the median for a typical document and the p90/p95 for the worst case.
Latency is measured only on successful runs (n is each system's success count, and the Avg pages column is the average length of those documents). Failures and timeouts contribute no latency and are excluded, not capped: a failed run persists no latency value, and a timed-out run leaves no output to time. A system that gives up on a hard document therefore is not penalized by this metric.
Because of this, latency must be read against coverage: no two systems are timed over the same workload. The full-coverage systems are timed on far longer documents on average (Reducto 367, Extend 309 pages) than any frontier model (86–121 pages), because the long documents that produce long latencies are exactly the ones the frontier models failed to complete. Gemini's low, tight latency is therefore not evidence of speed on hard documents. Datalab Extract (Balanced) is the slowest system by a wide margin (mean 1,609s, p95 4,928s) even though its completed documents average only 110 pages - so unlike the full-coverage systems, its latency is not explained by being handed longer documents.
8. Findings & Implications
- Recall is the greatest differentiator. Precision and leaf accuracy are high almost everywhere; recall (getting all the rows out of a dense document) is what separates the field.
- Completeness is a real challenge. Most systems are reasonably accurate on what they return. The benchmark is decided by how much of a dense corpus a system can return at all.
- In this benchmark, direct frontier LLM calls were less robust than dedicated extraction systems on long, dense documents. Called directly, they break on the defining property of this corpus (size) via truncation, context limits, page caps, and schema rejections. Their strong accuracy on the documents they finish does not carry to the larger scale documents.
- The strongest dedicated extraction platforms add real robustness over raw LLMs (Extend and LlamaExtract finish 90%+ of the corpus vs. ~50% for the lowest coverage frontier models).
9. Limitations
This benchmark aims to be a fair, reproducible comparison, but its scope and provenance carry caveats that should be read alongside the results:
- Sponsorship. Reducto commissioned this benchmark. Reducto is also one of the systems under test and the top performer on these documents.
- Methodology provenance. Reducto authored parts of the methodology and the ground truth generation harness.
- Model-assisted ground truth. Ground truth was drafted with frontier models and then reconciled by hand; it was not written from scratch by humans for every document.
- Label bias. AI-drafted labels can carry the biases of the models that produced them, including blind spots shared with the systems being graded - a model may be scored generously where it errs in the same way the labeler did.
- Different classes of system. Direct frontier-LLM API calls are not equivalent to dedicated extraction platforms. This compares two different classes of system, with different interfaces, defaults, and intended use, on a single task formulation.
- Scope. Results are specific to this corpus, schema setup, provider configurations, and run date. Provider models and services change over time; numbers may not reproduce on a later run.
- Sampled label checks. Agreement-field sampling provides evidence that the labels are sound, not a mathematical guarantee that the full corpus is correct. Unsampled documents could contain label errors that this process would not surface.
- Reproducibility. The evaluation harness, grading methodology, provider adapters, and benchmark implementation are available in the accompanying GitHub repository. Due to licensing and commercial restrictions, the full benchmark corpus is not publicly released. A representative subset of 50 benchmark tasks is provided to illustrate the methodology and enable inspection of the evaluation pipeline.
.png)

.webp)
.webp)
